

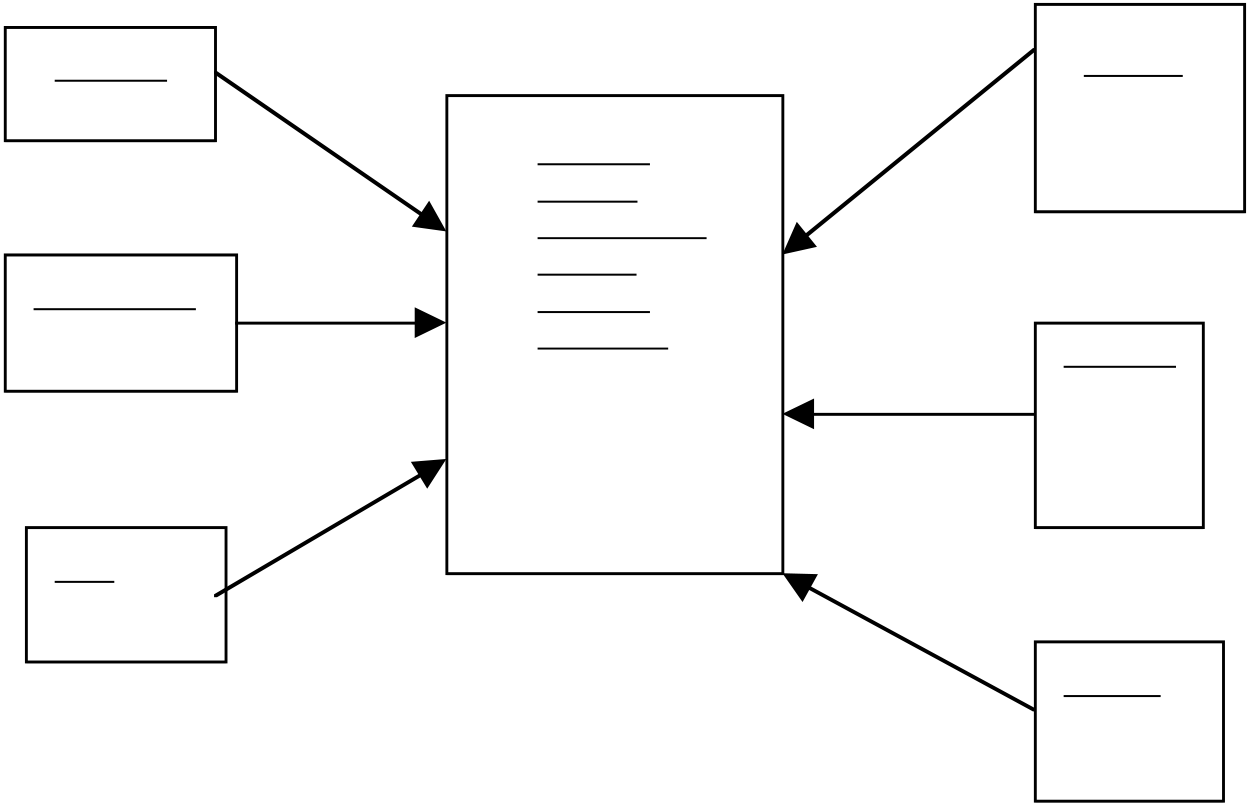
Will use the star schema shown figure
The cross tabulation in this example is a 2D (two dimensional) aggregation. But this is just a special case. For example, if other automobile models (such as Dodge, Ford, etc.) are added, it becomes a 3D aggregation. Generally speaking, the traditional GROUP BY clause in SQL can be used to generate the core of the N-dimensional data cube. The N-1 lower-dimensional aggregates appear as points, lines, plains, cubes or hyper-cubes in the original data cube. For this reason, a data CUBE operator was proposed [Gray, Bosworth, Layman and Pirahesh 1996].
| Fact table | ProdNo | |
|---|---|---|
|
OrderNo | ProdName |
| ProdColor | ||
| Category | ||
| StoreID | ||
|
CustomerNO | Date |
| ProdNo | ||
| DateKey | ||
| CityName | DateKey | |
| Sales | ||
| Date | ||
| Profit | ||
| Month | ||
| Sales | Quarter | |
| Year | ||
|
||
| City | ||
|
| Figure 11.2 A star schema |
|---|
© 2000 by CRC Press LLC
11.1 and Table 11.4 will be frequently cited by examples in the rest of this chapter.
| RID | Product |
|
|||
|---|---|---|---|---|---|
|
|
11.3.3.5 Granularity and aggregation levels
In OLAP, data can be examined at different levels.11.4.1 REVIEW OF A POPULAR DEFINITION
Earlier in Chapter 4, we provided a brief discussion on data warehouses based on a business perspective. However, this discussion requires some further technical clarification. For example, we said that a data warehouse consists of a copy of data acquired from the source data. What does this copy look like? In fact, we may need to distinguish between a "true" copy (duplicate), a derived copy, approximate duplicate, or something else. For this reason, we need to examine the concept of data warehouse in more depth. In fact, a data warehouse can be characterized using materialized viewsand indexing. In the following, we will examine these two issues.© 2000 by CRC Press LLC




