Theorem and bayesian inferencebayes theorem
|
|---|
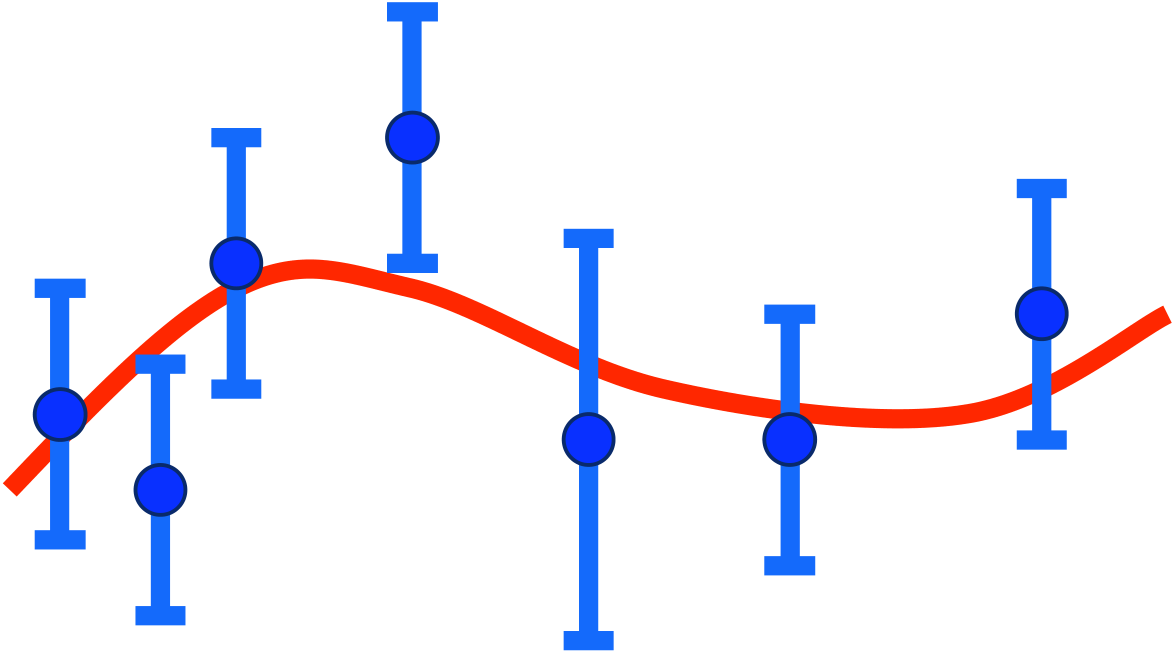
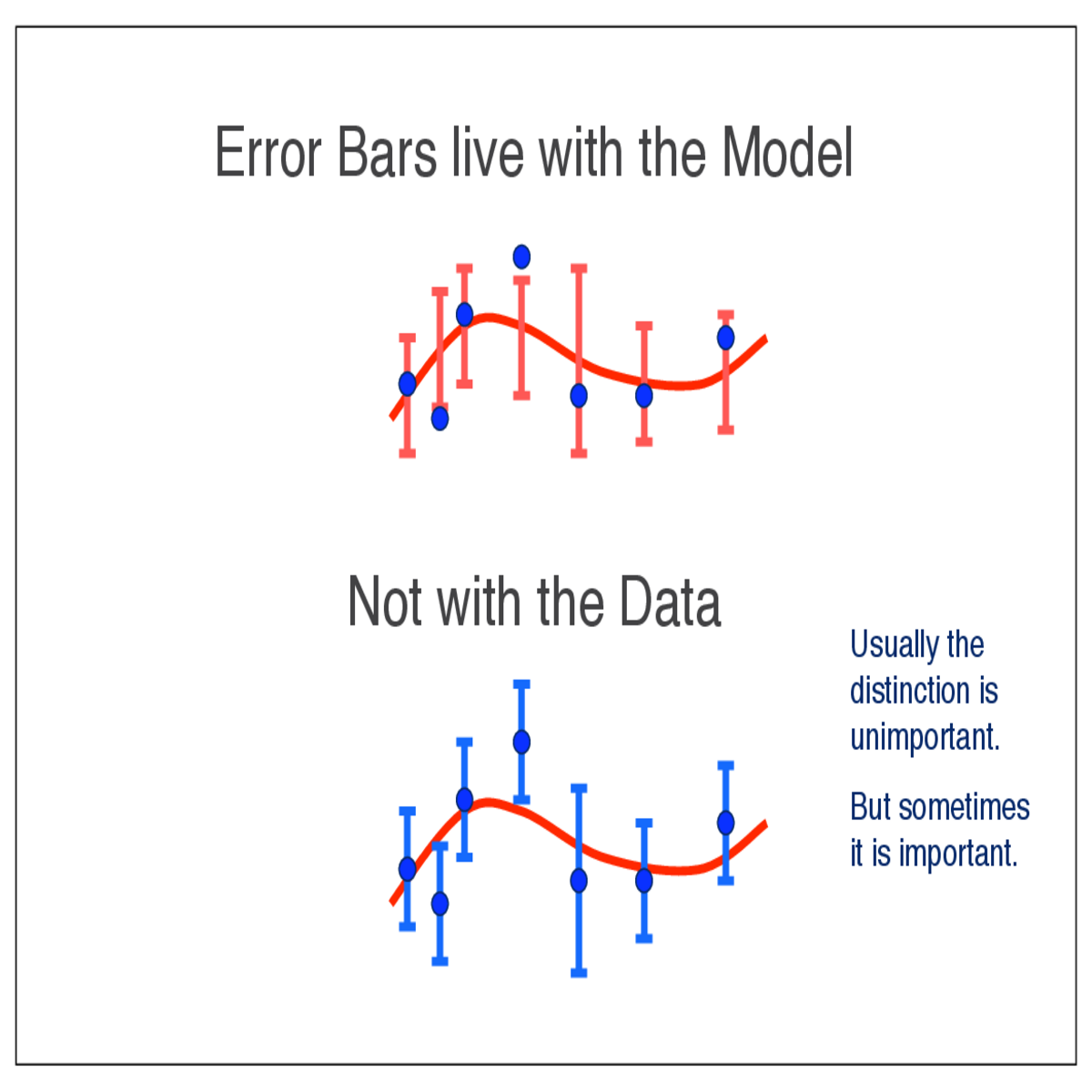
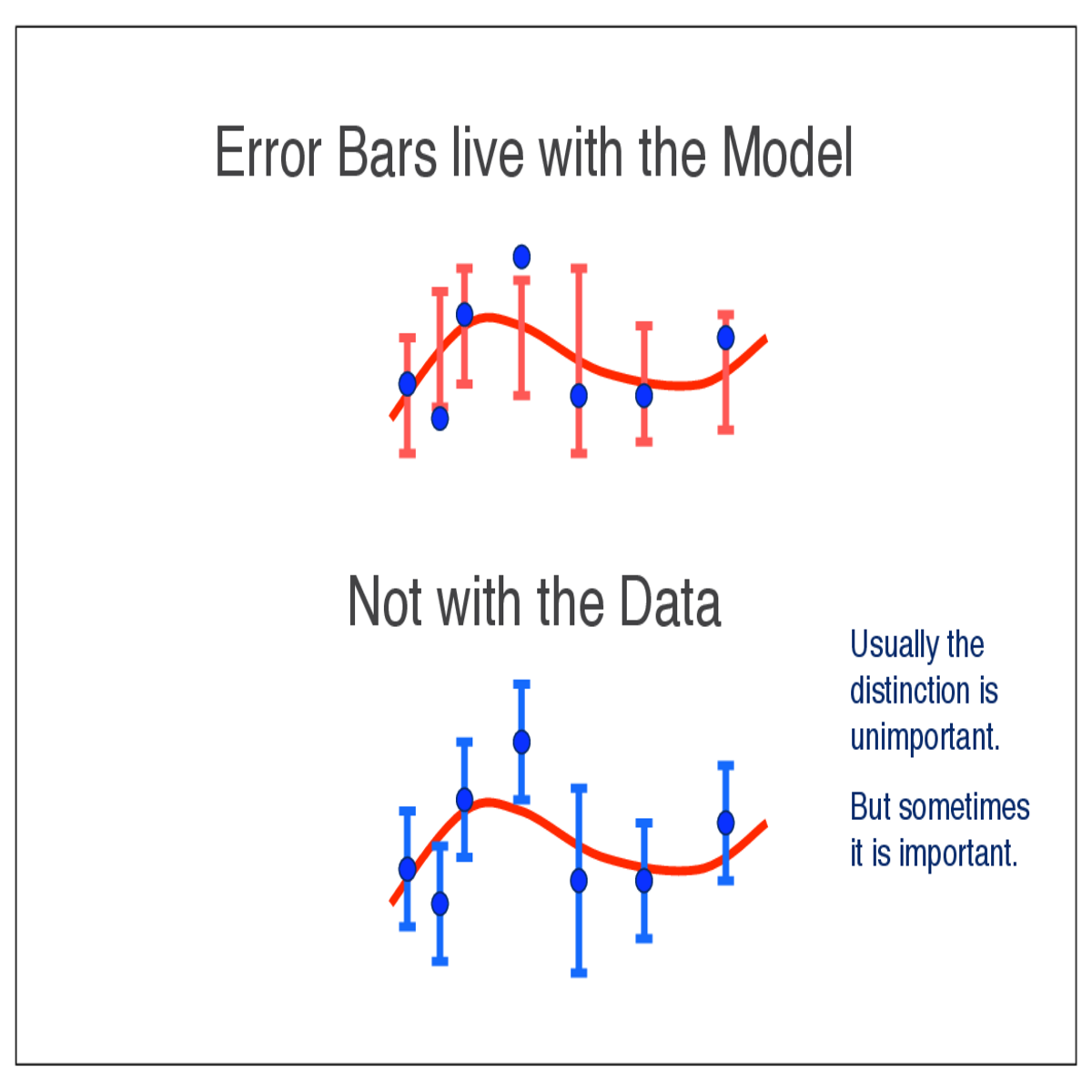
Error bars live with the model, not the data!
| Example: Poisson data: |
|
Xi | 15 | i | λ | 20 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||
|
||||||||||||||
| Xi = �, �2(Xi) = � | 0 | 5 | ||||||||||||
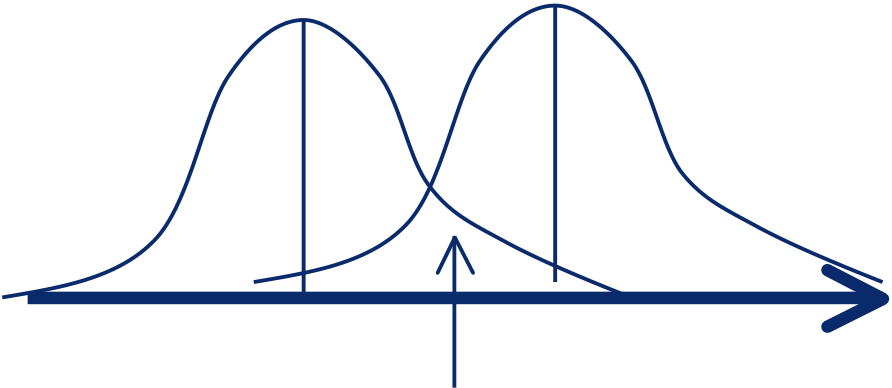
| How to attach error bars to the data points? | ||||||||||||||
| The wrong way: |
|
|
||||||||||||
| and ˆ X � | ||||||||||||||
| i� | ||||||||||||||
Assigning σ(Xi )= √ Xi gives a downward bias. Points lower than average by chance are given smaller error bars, and hence more weight than they deserve.
The right way:�
|
|||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Y |
|---|

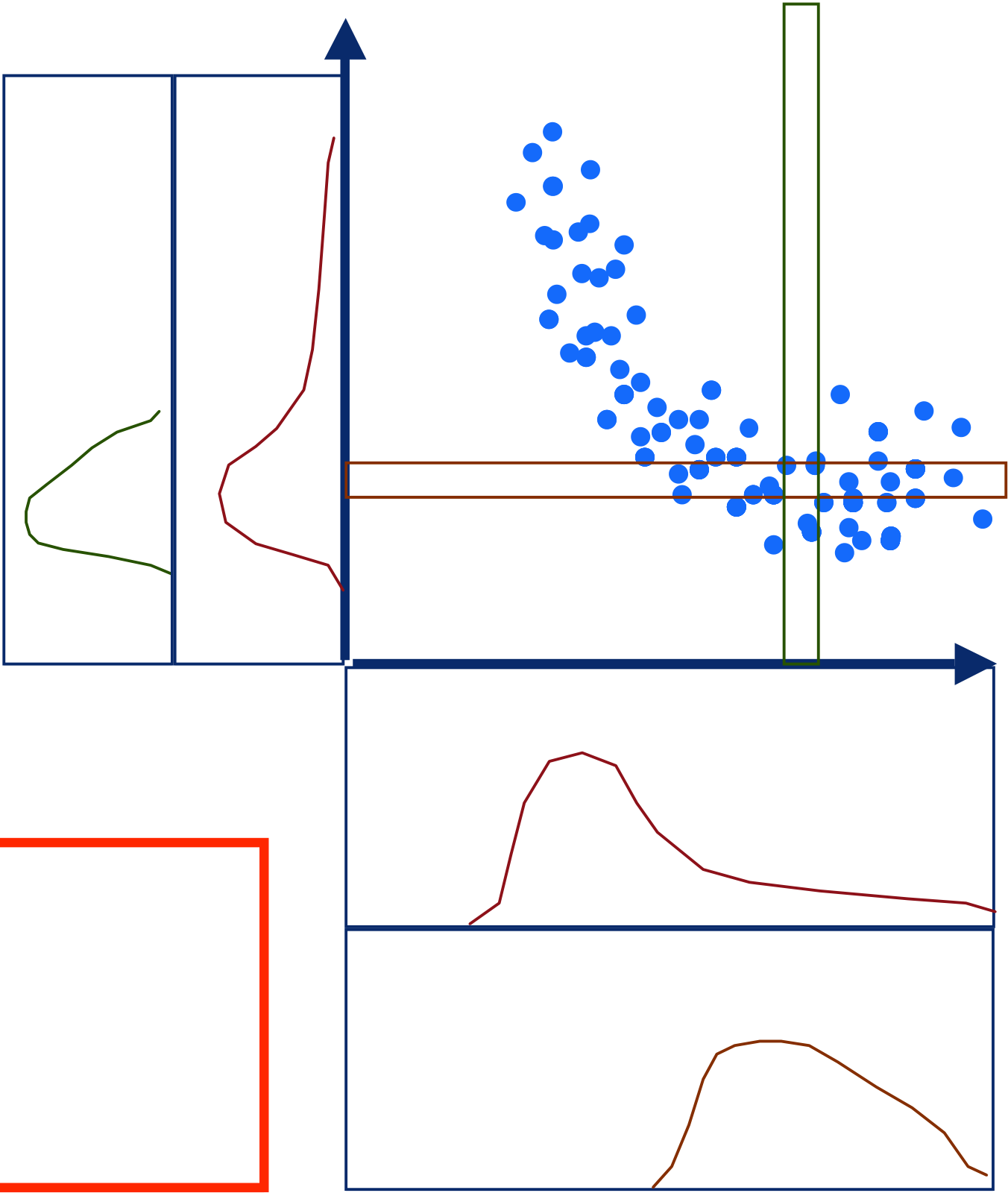
P( Y | X = 2 ) = ?
6 Y
Y = 3 X
X = Gaussian1 2 3 X
|
||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|---|
|
|---|
X
|
α | ||
|---|---|---|---|
|
|||
|
|||
|
|
Model | X2 |
|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Gaussian Datum with Gaussian Prior
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Gaussian Data with Gaussian Prior
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Max Likelihood for Gaussian Data Likelihood of parameters α for a given dataset:
| � | N | ||
|---|---|---|---|
| � | |||
| i=1 |
For Gaussian error distributions:
| � |
|
= | e |
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2� � i | |||||||||||
� i=1 |
1 |
|
|||||||||
| � i | |||||||||||
| �2 lnL = �2+ 2 | ln� i + N ln 2� | ||||||||||
2
Var[�ML] � � �2 �
| � To maximise L(�), minimise �2+ 2 i� |
|---|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i |
|
|
|---|---|---|
|
||
|
||
|
| Poisson data X with rate parameter λ : | 4 | 2 | 4 | 6 | 8 | Xi | 10 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | |||||||||||||||||||||||
| 0 | |||||||||||||||||||||||
| 0 | |||||||||||||||||||||||
| 0.3 | λ=1 | ||||||||||||||||||||||
| Likelihood for N Poisson data points : | 0.25 | ||||||||||||||||||||||
|
|||||||||||||||||||||||
| 0.2 | |||||||||||||||||||||||
|
L(�) = | N | P(Xi | �) | = | N | ||||||||||||||||||
| 0.15 | |||||||||||||||||||||||
| λ=7 | |||||||||||||||||||||||
| � | � | ||||||||||||||||||||||
| 0.1 | |||||||||||||||||||||||
| i=1 | i=1 | 0.05 | � | 6 | 8 | 10 | |||||||||||||||||
| lnL = | i� | ( � � + Xi ln� � ln Xi! | |||||||||||||||||||||
| 0 | |||||||||||||||||||||||
| 2 | 4 | ||||||||||||||||||||||
| Maximum likelihood estimator of λ : | 1.2 |
|
|
4 | � | ||||||||||||||||||
| 1 | |||||||||||||||||||||||
| i� | Xi | ||||||||||||||||||||||
| 0.8 | |||||||||||||||||||||||
| 0.6 | |||||||||||||||||||||||
| 0.4 | |||||||||||||||||||||||
| 0.2 | |||||||||||||||||||||||
| 6 | 8 | 10 | |||||||||||||||||||||
| � |
|
Xi |
|
||||||||||||||||||||
| 0 | |||||||||||||||||||||||
| -0.2 | |||||||||||||||||||||||
| � | |||||||||||||||||||||||




