

The second phase the tool flow shown the bottom half figure

|
|---|
lenging AI domains such as computer vision and natural language processing, their computational demands have steadily outpaced the performance growth rate of standard CPUs. These trends have spurred a Cambrian explosion of specialized hardware, as large companies, startups, and research efforts shift en masse towards energy-efficient accelerators such as GPUs, FPGAs, and neural pro-cessing units (NPUs)1-3 for AI workloads that demand performance beyond mainstream proces-sors.
| IEEE Micro | 8 | Published by the IEEE Computer Society |
|---|---|---|
| March/April 2018 | 0272-1732/18/$33.00 ©2018 IEEE |
IEEE MICRO
The rest of this article describes the Project Brainwave system in detail. We provide background on the system and tool chain that translates high-level models onto Brainwave NPUs. We then describe the soft NPU architecture, its microarchitecture, and implementation. Finally, we de-scribe how Brainwave is used within Bing.
BACKGROUND
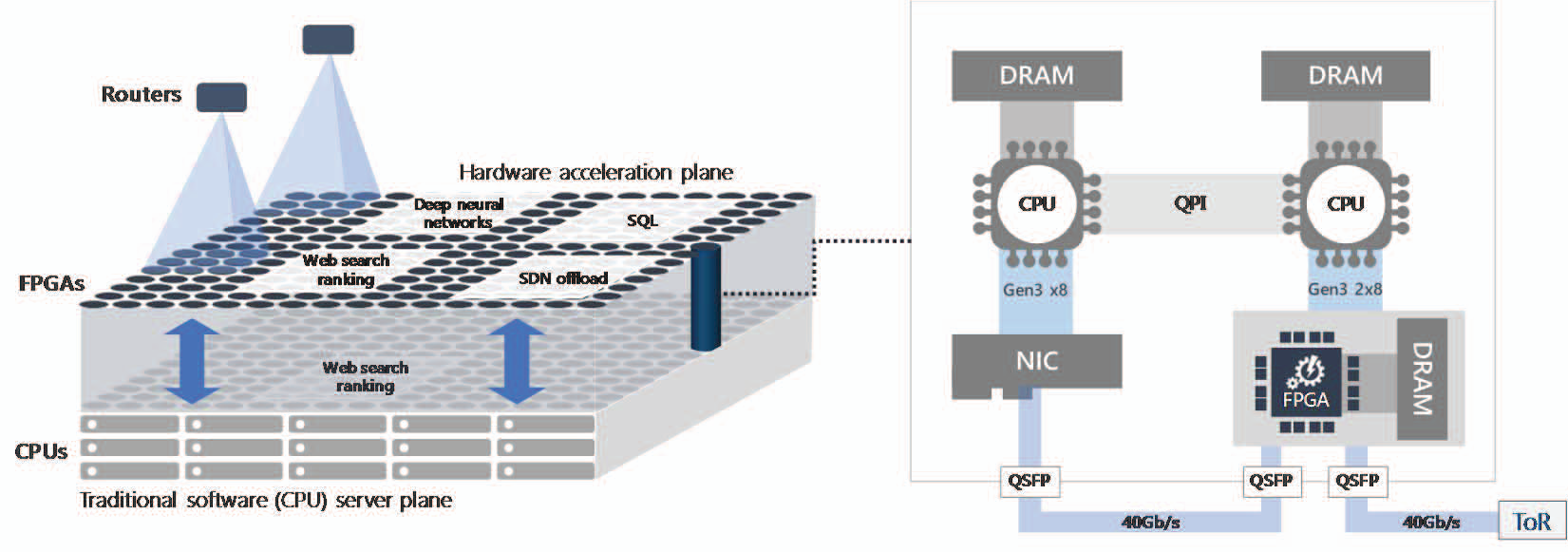
Figure 1. The first generation of Catapult-enhanced servers in production (right) consists of dual Xeon CPUs with a PCI Express (PCIe)-attached FPGA. Each FPGA sits in-line between the 40 gigabits per second (Gbps)-server NIC and the TOR, enabling in-situ processing of network packets and point-to-point connectivity with up to hundreds of thousands of other FPGAs at datacenter scale. Multiple FPGAs can be allocated as a single shared hardware microservice with no software in the loop (left), enabling scalable workloads and better load balancing between CPUs and FPGAs.
There is an important synergy between on-chip pinning and the integration with hardware micro-services. When a single FPGA’s on-chip memory is exhausted, the system user can allocate more FPGAs for pinning the remaining parameters by scaling up a single hardware microservice and leveraging the elasticity of cloud-scale resources. This contrasts to single-chip NPUs (with no direct connectivity to other NPUs) designed to execute models stand-alone. Under these con-straints, exploiting pinning would require scaling down models undesirably to fit into limited single-device on-chip memory, or it would require spilling of models into off-chip DRAM, in-creasing the single-batch serving latencies by an order of magnitude or more.
| March/April 2018 | 10 | www.computer.org/micro |
|---|

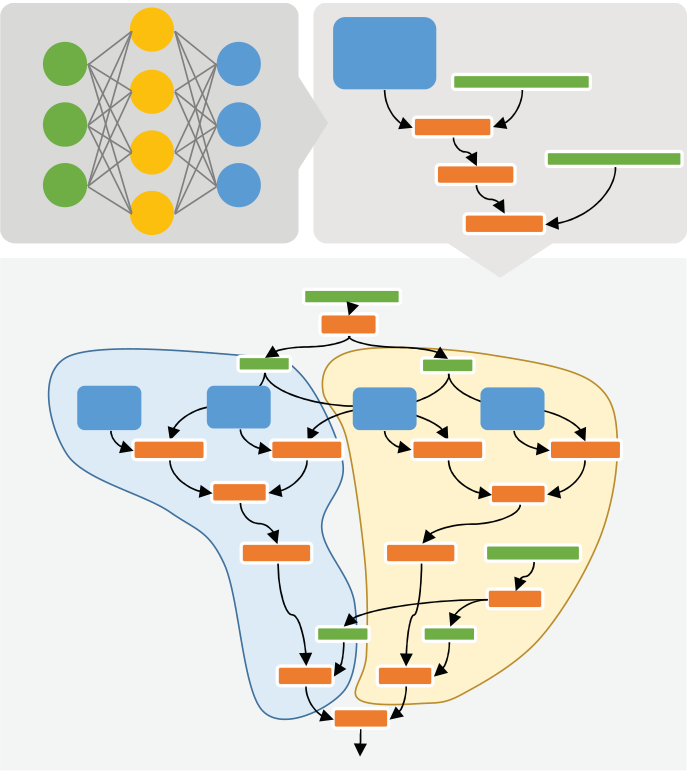
Figure 2. The three major layers of the Brainwave system: (left) a tool flow that converts pre-trained DNN models to a deployment package, (middle) a scalable DNN hardware microservice with network-attached FPGAs, and (right) the programmable Brainwave NPU hosted on FPGA.
Figure 3 illustrates the tool flow that converts DNN models into a deployable hardware micro-service. A pre-trained DNN model developed in a framework of choice (such as Cognitive Toolkit (CNTK)7 or TensorFlow (TF)8) is first exported into a common graph intermediate rep-resentation (IR). Nodes in the IR represent tensor operations (such as matrix multiplication), while edges delineate the dataflow between operations.
| Caffe | CNTK | |
|---|---|---|
| Model | Model |
S p lit
| Deployment Package | A d d 5 0 0 | 5 0 0 | C o n c a t | A d d 5 0 0 |
|---|---|---|---|---|
| FPGA HW Microservice |
employed depending on layer type and degree of optimization. CNNs, due to their high computa-tional intensity, are typically mapped to single FPGAs, while matrix weights of bandwidth-lim-ited RNNs are pinned in a greedy fashion across multiple FPGAs during depth-first traversal of the DNN graph. Large matrices that cannot fit in a single device are sub-divided into smaller ma-trices. More sophisticated methods that factor in the cost of communication can be applied dur-ing optimization but are less critical because the datacenter network latencies we observe are small (a few �s) relative to compute times (a few ms).
Operators that are unsupported or not profitable for offload are grouped into sub-graphs assigned to CPUs. This heterogeneous approach preserves operator coverage by leveraging CPUs as a catch-all for currently unsupported or rarely exercised operators (over time, however, nearly all performance-critical operators will be served on FPGAs). Users of the tool flow can also pre-cisely control selection of sub-graphs and their assignments to specific resources using annota-tions in the model description. The second phase of the tool flow is shown in the bottom half of Figure 3, where partitioned sub-graphs are passed down to device-specific backend tools. Each backend may map sub-graphs into optimized libraries (such as advanced vector extensions (AVX)-tuned BLAS kernels on x86 CPUs) or compile optimized assembly automatically.
The Brainwave NPU is a parameterized soft vector processor at the heart of the Brainwave sys-tem. Its salient features include:
•the use of compile-time narrow precision data types to extract higher performance than what is possible using conventional float and integer types without losses in accuracy; •a simple, single-threaded programming model with an extensible ISA that can adapt to fast-changing DNN algorithms; and
•a scalable microarchitecture that maximizes hardware efficiency at low batch sizes.
| March/April 2018 | 12 | www.computer.org/micro |
|---|
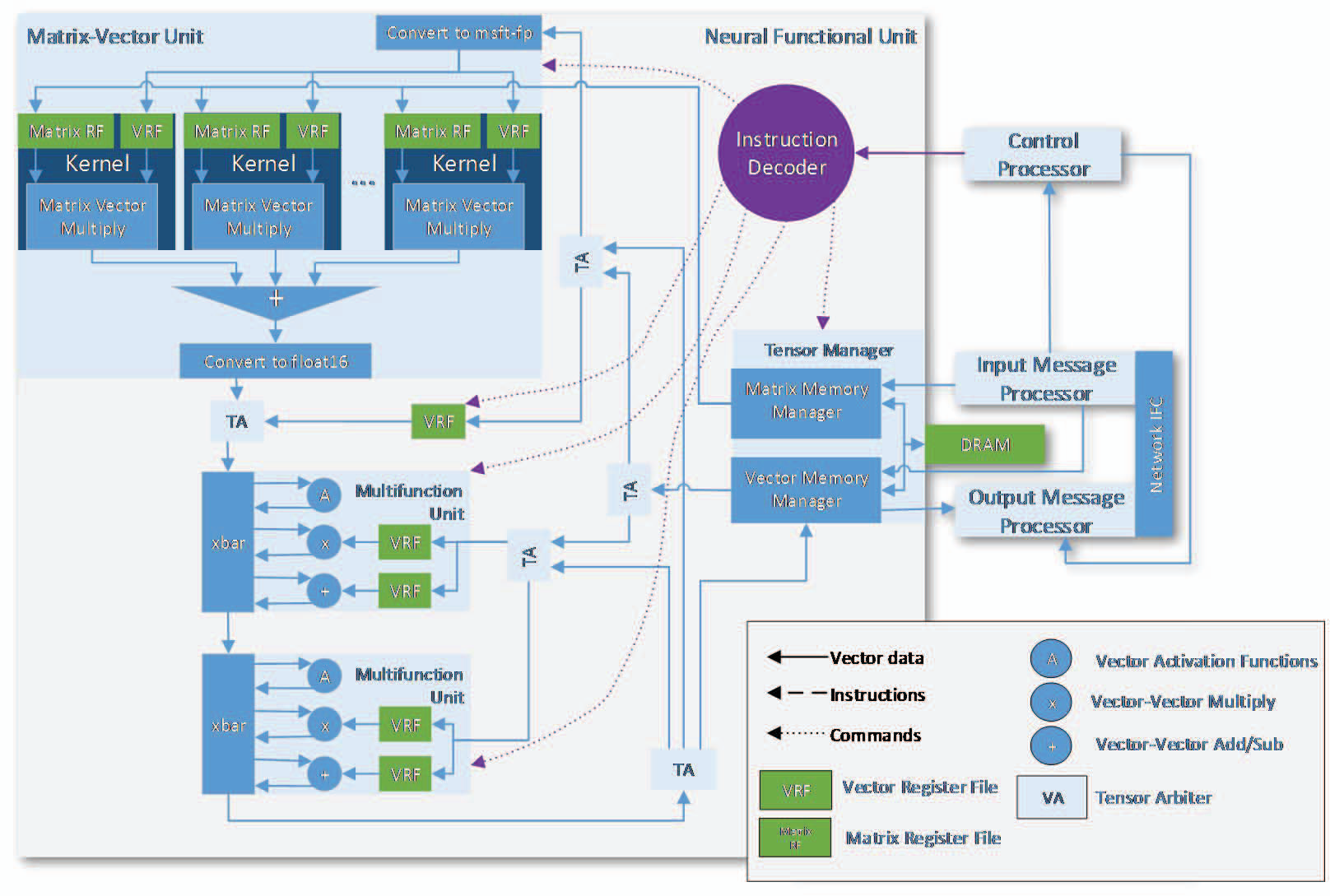
Figure 4. The Brainwave NPU is a “mega-SIMD” vector processor architecture. A sequentially programmed control processor asynchronously controls the neighboring NFU, optimized for fast DNN operations. The heart of the NFU is a dense matrix-vector multiplication unit (MVU) capable of processing single DNN requests at low batch with high utilization. The MVU is joined to secondary multifunctional units (MFUs) that perform element-wise vector-vector operations and activation functions.
HOT CHIPS
synaptic weights of neurons, while rows of the activation matrix represent independent inputs to the neural layer.
| �������� | ���� | � � |
|
|||
|---|---|---|---|---|---|---|
|
Applying the system-level strategy of on-chip pinning discussed previously, the Brainwave NPU leverages the abundant independent on-chip memory resources of FPGAs to pin and serve DNN weight parameters to MAC units (without reload between independent DNN requests to the NPU). A contemporary Intel Stratix 10 280 FPGA, for example, has 11,721 independently ad-dressable 512x40b SRAMs, and, in aggregate, provides 30 MB of on-chip storage and 35 tera-bytes per second of bandwidth at 600 MHz. Typical instances of Brainwave NPUs on Stratix 10 allocate storage for tens of millions of parameters and hundreds of thousands of vector elements. While pinning is the default strategy for most neural networks, DRAM can also be used for buff-ering activations and weights.
As shown in Figure 5, multi-lane vector dot product units form the bulk of the MVU. Locally attached SRAMs feed each MAC with unique weight values, enabling full-chip utilization of memory-intensive matrix-vector multiplication operations. Although the MACs operate in lower precision, their internal data types are transparent to the overall NPU and software (through in-situ hardware converters), which operate in float16 for I/O and non-dot product operations.
| March/April 2018 | 14 | www.computer.org/micro |
|---|
precision even further is possible without losses in accuracy. Based on accuracy-sensitivity stud-ies of internal production and public DNN models (such as ResNet), we have developed proprie-tary “neural”-optimized data formats based on 8- and 9-bit floating point, where mantissas are trimmed to 2 or 3 bits. These formats, referred to as ms-fp8 and ms-fp9, exploit efficient packing into reconfigurable resources and are comparable in FPGA area to low bit-width integer opera-tions but can achieve higher dynamic range and accuracy than pure fixed-point implementations. We have found that the versatility of these formats simplifies the quantization process of neural networks considerably relative to conventional 8-bit fixed point, where significant fine-tuning in the radix point is needed to preserve accuracy.
Figure 6 shows three internal production models that quantize effectively to ms-fp9. A non-re-trained conversion results in a minimal degradation in accuracy (1 to 3 percent), which can be fully recovered with just 1 to 3 epochs of quantized retraining. When optimized for ms-fp8 and ms-fp9 arithmetic, the Brainwave NPU can achieve high levels of MAC density and peak perfor-mance. Figure 7 compares peak Tflops when precision is varied, showing up to Tflops of peak performance on a Stratix 10 280 at ms-fp8. Note that these levels of performance are comparable to high-end hard NPUs and contemporary GPUs implemented with higher-precision fixed-point arithmetic.
Figure 6. The impact to accuracy of various DNN production models is negligible with post-trained quantization into narrow precision ms-fp. With re-training, accuracy can be fully recovered.
| 500.0 |
|
||||
|---|---|---|---|---|---|
| TERA-OP/SEC |
5.0 |
30.7 | |||
| 5.2 | |||||
| 2.7 |
|
||||
| 1.4 | 2.0 | ||||
| 0.5 | |||||
| 16-bit int |
|
||||
RESULTS
Accelerating Bing Intelligent Search
| Bing TP1 | |||
|---|---|---|---|
| CPU-only | Brainwave-accelerated | Improvement | |
| Model details | GRU 128x200 (x2) + W2Vec |
|
|
| 9 ms | 0.850 ms | ||
| Bing DeepScan | |||
| CPU-only | Brainwave-accelerated | Improvement | |
| Model details | |||
|
15 ms | 5 ms | |
Brainwave NPU on Pre-production Stratix 10 280
With production tools and silicon, the design should comfortably reach 550 MHz, for an addi-tional 83-percent gain. In terms of energy efficiency and power, the Stratix 10 consumes 125 W when measured with a fully loaded power virus. On production silicon, the expected energy effi-ciency at peak throughput is 720 giga-ops per second per watt (GOPs/W).
CONCLUSION
|
|
|---|
REFERENCES
1. J. Ouyang et al., “SDA: Software-defined accelerator for large-scale DNN systems,” IEEE Hot Chips 26 Symposium (HCS), 2014;
http://ieeexplore.ieee.org/document/7478821/.6. Y. Chen et al., “DaDianNao: A Machine-Learning Supercomputer,” 47th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2014; http://ieeexplore.ieee.org/document/7011421/.
7. F. Seide and A. Agarwal, “CNTK: Microsoft’s Open-Source Deep-Learning Toolkit,” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016;
https://dl.acm.org/citation.cfm?id=2945397.
| March/April 2018 | 18 | www.computer.org/micro |
|---|
IEEE MICRO
Kalin Ovtcharov is a senior research hardware development engineer at Microsoft. Contact him at kaovt@microsoft.com.
Daniel Lo is a senior research hardware development engineer at Microsoft. Contact him at dlo@microsoft.com.
Shlomi Alkalay is a senior software engineer at Microsoft. Contact him at salkalay@mi-crosoft.com.
Christian Boehn is a senior software engineer at Microsoft. Contact him at cboehn@mi-crosoft.com.
Derek Chiou is a partner group hardware engineering manager at Microsoft. Contact him at dechiou@microsoft.com.
Stephen Heil is a principal program manager at Microsoft. Contact him at ste-phen.heil@microsoft.com.
Kyle Holohan is a senior software engineer at Microsoft. Contact him at kyle.holohan@mi-crosoft.com.
Sitaram Lanka is a partner group engineering manager at Microsoft. Contact him at slanka@microsoft.com.
HOT CHIPS
Amanda Grace Rapsang is a principal software engineer at Microsoft. Contact her at agrace@microsoft.com.
Steven K. Reinhardt is a partner hardware engineering manager. Contact him at ste-ver@microsoft.com.
Balaji Sridharan is a software engineer at Microsoft. Contact him at balba@mi-crosoft.com.
Gabriel Weisz is a senior hardware engineer at Microsoft. Contact him at ga-briel.weisz@microsoft.com.
Doug Burger is a Distinguished Engineer at Microsoft. Contact him at dburger@mi-crosoft.com.
| March/April 2018 | 20 | www.computer.org/micro |
|---|




