

The recommended and supported operating system for sap hana
|
|---|
Fabian Herschel, Distinguished Architect SAP (SUSE)
Bernd Schubert, SAP Solution Architect (SUSE)
Date: 2022-12-07
SUSE® Linux Enterprise Server for SAP Applications is optimized in various ways for SAP* applications. This guide provides detailed information about installing and customizing SUSE Linux Enterprise Server for SAP Applications for SAP HANA system replication in the performance optimized scenario. The document focuses on the steps to integrate an already installed and working SAP HANA with system replication. It is based on SUSE Linux Enterprise Server for SAP Applications 15 SP3. The concept however can also be used with SUSE Linux Enterprise Server for SAP Applications 15 SP1 or newer.
SUSE is accommodating this development by offering SUSE Linux Enterprise Server for SAP Applications, the recommended and supported operating system for SAP HANA. In close collab-oration with SAP, cloud service and hardware partners, SUSE provides two resource agents for customers to ensure the high availability of SAP HANA system replications.
1.1.1 Abstract
multi-tier (chained) system replication
multi-target system replication
| 4 | ||
|---|---|---|
| SAP HANA System Replication Scale-Up - Performance Optimized Scenario |

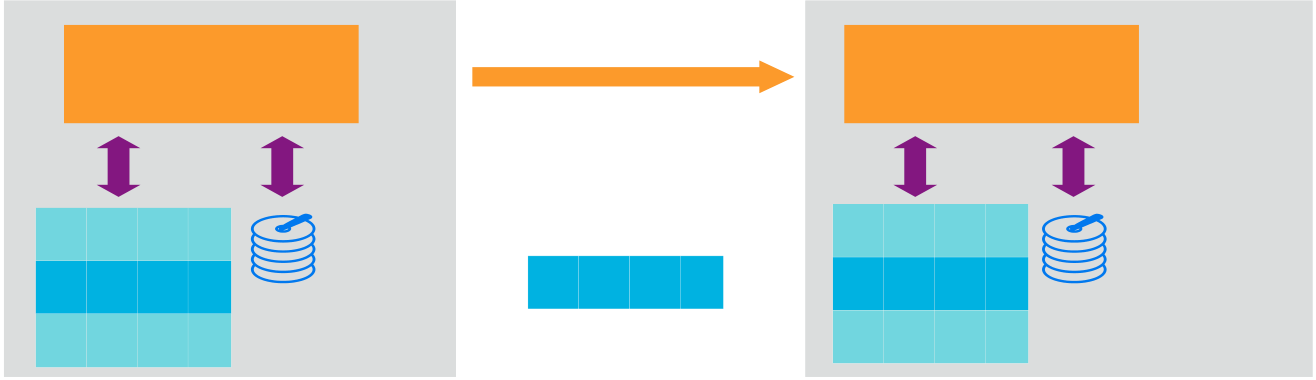
On-premises deployment on physical and virtual machines
1.1.2 Scale-up versus scale-out
The rst set of scenarios includes the architecture and development of scale-up solutions.
System
Replication
| A | A | B | A |
|---|
The second set of scenarios includes the architecture and development of scale-out solutions (multi-box replication). For these scenarios, SUSE has developed the scale-out resource agent package SAPHanaSR-ScaleOut .
5 SAP HANA System Replication Scale-Up - Performance Optimized Scenario
With this mode of operation, internal SAP HANA high availability (HA) mechanisms and the resource agent must work together or be coordinated with each other. SAP HANA system repli-cation automation for scale-out is described in a separate document available on our documen-tation Web page at . The document for scale-out is named "SAP HANA System Replication Scale-Out - Performance Optimized Scenario".
1.1.3 Scale-up scenarios and resource agents
| 6 | Performance optimized (A ⇒ B). This scenario and setup is described in this document. | |
|---|---|---|
| SAP HANA System Replication Scale-Up - Performance Optimized Scenario |
System Replication
| SAP HANA | vIP |
|
PRD | |
|---|---|---|---|---|
| primary |
In the performance optimized scenario an SAP HANA RDBMS site A is synchronizing with an SAP HANA RDBMS site B on a second node. As the SAP HANA RDBMS on the second node is configured to pre-load the tables, the takeover time is typically very short. One big advance of the performance optimized scenario of SAP HANA is the possibility to allow read access on the secondary database site. To support this read enabled scenario, a second virtual IP address is added to the cluster and bound to the secondary role of the system replication.
In the cost optimized scenario, the second node is also used for a stand-alone non-repli-cated SAP HANA RDBMS system (like QAS or TST). Whenever a takeover is needed, the non-replicated system must be stopped rst. As the productive secondary system on this node must be limited in using system resources, the table preload must be switched o. A possible takeover needs longer than in the performance optimized use case.
In the cost optimized scenario, the secondary needs to be running in a reduced memory consumption configuration. This is why read enabled must not be used in this scenario. As already explained, the secondary SAP HANA database must run with memory resource restrictions. The HA/DR provider needs to remove these memory restrictions when a takeover occurs. This is why multi SID (also MCOS) must not be used in this scenario.
| SAP HANA | |||||
|---|---|---|---|---|---|
| SAP HANA | SAP HANA | ||||
| SAPHanaTopology | primary | secondary |
|
secondary | |
| vIP | vIP | PRD | |||
| SAP HANA | SAP HANA | ||||
| primary | secondary | ||||
| PRD | PRD | ||||
FIGURE 5: SAP HANA SYSTEM REPLICATION SCALE-UP IN THE CLUSTER - PERFORMANCE OPTIMIZED CHAIN
FIGURE 6: SAP HANA SYSTEM REPLICATION SCALE-UP IN THE CLUSTER - PERFORMANCE OPTIMIZED MULTI-TARGET
Multi-tier and multi-target systems are implemented as described in this document. Only the rst replication pair (A and B) is handled by the cluster itself.
To achieve an automation of this resource handling process, you must use the SAP HANA re-source agents included in SAPHanaSR. System replication of the productive database is auto-mated with SAPHana and SAPHanaTopology.
The cluster only allows a takeover to the secondary site if the SAP HANA system replication was in sync until the point when the service of the primary got lost. This ensures that the last commits processed on the primary site are already available at the secondary site.
|
|
|---|
Chapters in this manual contain links to additional documentation resources that are either available on the system or on the Internet.
.
Supported high availability solutions by SUSE Linux Enterprise Server for SAP Ap-plications overview:
SAP HANA SR Performance Optimized Scenario - Setup Guide - Errata
1.2.3 Feedback
Several feedback channels are available:
| 11 |
|
||
|---|---|---|---|
| . Make sure to include the document title, | |||
gle-box to single-box) system replication with the following configurations and parameters:
|
|||
|---|---|---|---|
| Both SAP HANA instances of the system replication pair (primary and secondary) have the | |||
| If the cluster nodes are installed in different data centers or data center areas, the envi- | |||
| ronment must match the requirements of the SUSE Linux Enterprise High Availability Ex- | |||
| tension cluster product. Of particular concern are the network latency and recommended | |||
| maximum distance between the nodes. Review the product documentation for SUSE Linux | |||
| Automated registration of a failed primary after takeover prerequisites need to be defined. | |||
| As a good starting configuration for projects, we recommend to switch o the au- | |||
| 13 | |||
|
|||
|
|||
| Multi-tenancy databases can be used in combination with any other setup (perfor- | |||
| In MDC configurations, the SAP HANA RDBMS is treated as a single system including | |||
|
|||
|
|||
| Tests on Multi-tenancy databases can force a different test procedure if you are using | |||
| Only one system replication between the two SAP HANA database in the Linux cluster. | |||
|
|||
| SAP HANA System Replication Scale-Up - Performance Optimized Scenario | |||
| Using SAPHanaSR.py is yet already mandatory for multi-tier and multi-target repli- | ||
|---|---|---|
| The Linux cluster needs to be up and running to allow HA/DR provider events being | ||
|
||
|
|---|
If susChkSrv.py parameter action_on_lost=stop is set and the RA SAPHana parameter AU-TOMATED_REGISTER=true is set, it depends on HANA to release all OS resources prior to the registering attempt.
16 SAP HANA System Replication Scale-Up - Performance Optimized Scenario


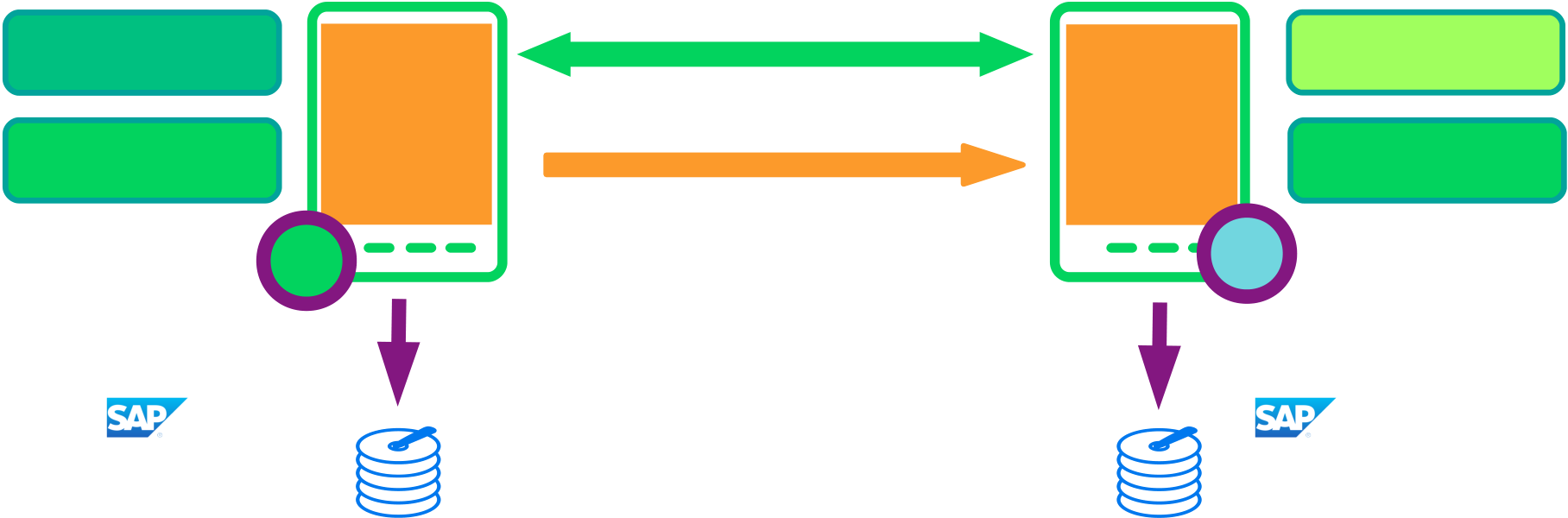
| SAP HANA | vIP | PR1 | ||
|---|---|---|---|---|
|
||||
| primary |
|
17 SAP HANA System Replication Scale-Up - Performance Optimized Scenario

| 18 | ||
|---|---|---|
| Database installation (see Section 6, “Installing the SAP HANA Databases on both cluster nodes”) | ||
| SAP HANA system replication setup (see Section 7, “Setting up SAP HANA System Replication” | ||
|
||
| SAP HANA System Replication Scale-Up - Performance Optimized Scenario |

Before you start, you need the following:
|
|
|
|---|
(2 node cluster):
1 optional IP address for HAWK Administration GUI
Requirements with 1 SAP instance per site (1 : 1) - with a majority maker (3 node cluster):
1 optional IP address for the read-enabled setup
1 optional IP address for HAWK Administration GUI




