

Introduction to types of nosql databases
“”NoSQL Databases
Introduction to types of NoSQL databases
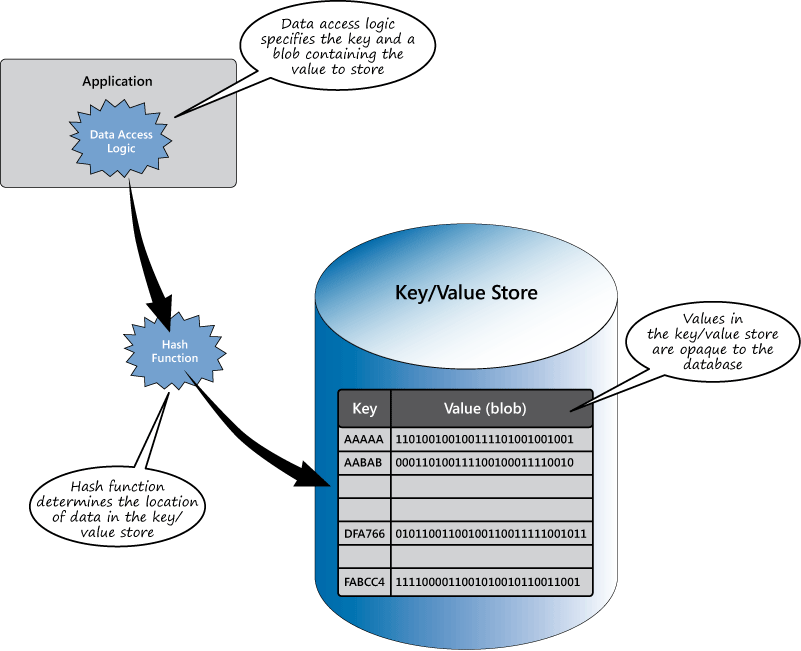
Key/Value Stores
A key/value store implements arguably the simplest of the NoSQL storage mechanisms, at least at a conceptual level. A key/value store is essentially a large hash table. You associate each data value with a unique key, and the key/value store uses this key to determine where to store the data in the database by using an appropriate hashing function.
Document Databases
Figure 4 - An example set of documents in a document database
The database in this example is designed to optimize query access to sales order information. In the application that uses this database, the most common operations performed on this data are queries that retrieve the details of each order. The details of the order are unlikely to change, so the denormalized structure imposes little overhead on updates while ensuring that queries can be satisfied with a single read operation.
single row in a column-family database can contain many columns. You group related
columns together into column families and you can retrieve columnar data for multiple
millions, or billions of rows containing hundreds of columns), while at the same time
providing very fast access to this data coupled with an efficient storage mechanism. A
Therefore, to make best use of a column-family database, you should design the column families to optimize the most common queries that your applications run.
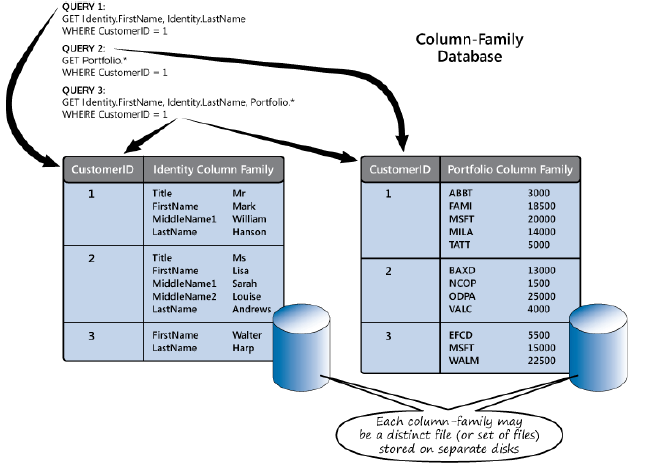
family (the term Portfolio.\* means all columns in the Portfolio column family). Only
QUERY 3 that combines the data to retrieve the names of customers and the shares that
Graph Databases
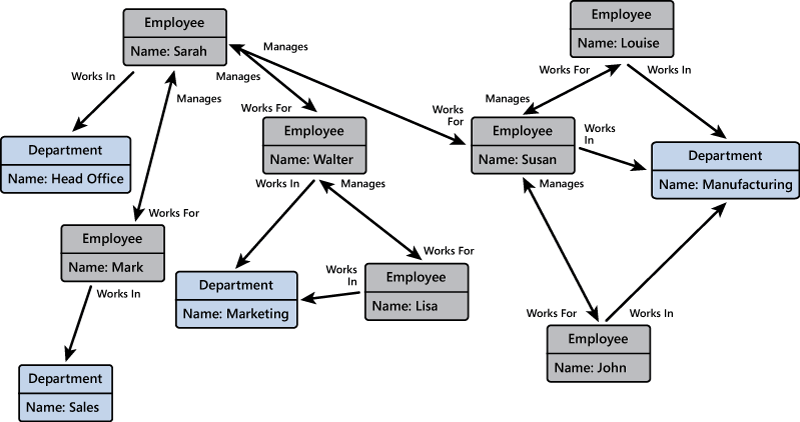
The purpose of a graph database is to enable an application to efficiently perform queries that traverse the network of nodes and edges, and to analyze the relationships between entities. Figure 9 shows an organization's personnel database structured as a graph. The entities are the employees and the departments in the organization, and the edges indicate reporting lines and the department in which employees work. In this graph, the arrows on the edges show the direction of the relationships.
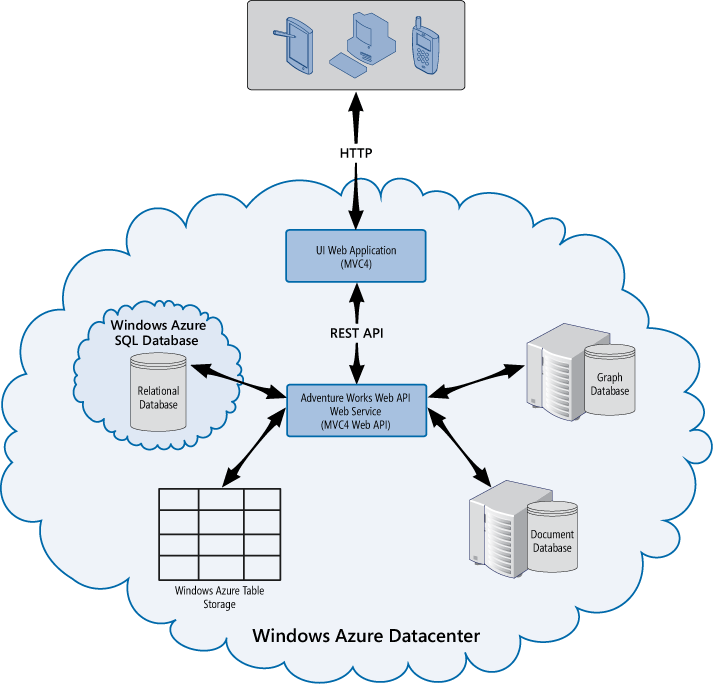
Integrating NoSQL Databases into a Polyglot Solution
Figure 13 - Implementing a web service as the integration point for multiple NoSQL databases
Some key/value stores implement data compression for values. This strategy reduces the size of the data that is stored at the expense of expanding the data when it is retrieved.
In the Shopping application, when a customer browses for products and adds the first item
contents of the shopping cart must be saved so that they can be made available the
next time the customer logs in.
Understanding Windows Azure Table Service Concepts
The Shopping application runs as a web application that uses the MvcWebApi web
not have to invest in expensive infrastructure to host the key/value store themselves.
Windows Azure actually provides two forms of storage; the Windows Azure Blob service
information. For the Shopping application, the developers at Adventure Works chose
the Table service because the data for each shopping cart is very unlikely to exceed
service, and defined the ShoppingCartTableEntity class shown in the following code
example to represent shopping cart information that the MvcWebApi web service stores
by using the contents of this shopping cart.
The value for the PartitionKey property is generated by the application to distribute shopping cart information evenly across partitions
base.RowKey = userId;
base.PartitionKey = ...;
public string ShoppingCartItemsJSON { get; set; }
public Guid TrackingId { get; set; }
ordered:
public class ShoppingCartItemTableEntity
public decimal ProductPrice { get; set; }
public string CheckoutErrorMessage { get; set; }
How Adventure Works Used a Document Database to Store the Product Catalog and Order History Information
you should consider the following factors:
How should you divide your data into documents and collections, and how far should you normalize or denormalize the data in a document?
as the Shopping application is concerned this data is all read-only. The category,
subcategory, and product information are good candidates for restructuring as product
customer.
Therefore, the developers chose to make a copy of each order as it is created and each time it is updated, and store these copies in a separate database, optimized for fast query access. The developers considered that a document database might provide better scalability and performance for holding this order history information than SQL Server.
The developers decided to use MongoDB to provide the document database. They
created two MongoDB collections in the database; categories which holds the
SQL Server database. The Shopping application also has to maintain a full audit trail of
each order, including a complete history of any changes made to each order. The
history information, especially as the database could contain tens of millions of orders.
Therefore, when a customer places a new order, the developers at Adventure Works
To enable order history information to be retrieved quickly, the developers adopted a
fully denormalized approach where each order history document includes the complete
How Adventure Works Plan to Store Information about Website
Traffic
design your column families carefully. You need to understand the data that your applications capture, and the queries that they need to perform over this data.
A well-designed column-family database enables an application to satisfy the majority of its queries by visiting as few column families as possible, while ensuring that the data held by each column family is relevant to the queries that reference them. In other words, you should partition the data that constitutes an entity vertically into sets of columns, where each set fully satisfies one or more queries but does not contain columns that are not required by most queries. Each set of columns is a candidate to become a column family. Ideally each column family should be non-overlapping (you should try and avoid duplicating the same data for the same row across different column families), although if the data is relatively static storing multiple copies of a column in different column families may help to optimize some queries.
How Adventure Works Used a Graph Database to Store Product Recommendations
The driving force behind most NoSQL databases is to enable you to store information in
To keep the list of product recommendations manageable and relevant, the list only contains the five most frequently purchased related products.
It is important to ensure that the application can find recommended products for any given product quickly and easily, so the developers at Adventure Works decided to store product recommendations in a graph database.
When a customer browses a product, the Shopping application uses the product ID to find the node for this product in the graph database and then it retrieves the list of recommended products by traversing the ProductRecommendation relationships from this node. To ensure that the application can locate the node for any given product quickly, the developers at Adventure Works created an index called product_id_index over the ProductId property in the RecommendedProduct nodes in the database.




